Athlon64系列处理器测试报告之技术解析篇
-
Athlon64――为你朝思暮想
关心AMD的人应该知道,AMD公司旧有的K7处理器Barton、Athlon XP由于EV6前端总线带宽、处理器核心频率提升能力不足等问题,在性能表现上不及Intel P4系列。
AMD要想在性能上同Intel继续竞争,必须依靠新的前端总线和处理器核心。为此,AMD公司早在3年前就放出新研制的K8核心处理器及其搭配的X86-64指令集的消息。
在这3年漫长的等待过程中,有关AMD公司产能有限,将被IBM兼并;AMD应用SOI技术制作新K8处理器时出现问题等流言通过各路媒介四处传播开来。终于在2003年9月中旬,继推出服务器平台的K8核心Opteron处理器系列之后,AMD排除万难推出了万众瞩目的AMD Athlon 64 FX51(支持双通道DDR400)和AMD Athlon 64(仅支持单通道DDR400)两个系列的桌面处理器,用事实给那些流言制造者们砸下了重重的一锤。
另一方面,针对Athlon 64系列的推出,Intel慌忙在2003年秋季的IDF论坛拿出了具备多达2MB三级缓存容量的P4 3.2GHz Exterem Edition处理器作为应对。稍加注意我们就可以发现,P4 EE同Intel的另一款支持多处理器系统的服务器CPU――Gallatin核心的Xeon MP规格非常相像,甚至可以说是Xeon MP去掉对多处理器支持的简化版。由此看来,为了对付Athlon 64系列,Intel可谓煞费苦心。
那么,让我们苦苦等待,迫使Intel不惜出动“服务器级“处理器大动干戈的Athlon 64系列究竟有哪些新看点呢?接下来,我们就在此为大家做一番详尽分析。
X86-64分析(一):我拥有你,但未必幸福
说到K8处理器,大家不免会想到AMD大肆宣传的X86-64指令集的概念。而要较为明晰地理解X86-64指令集,就必须从64位处理器的本质谈起。
●理解64位指令
我们都知道,处理器所处理的普通指令一般由操作码(OP Code)和操作数(Operand)组成。其中操作数可以是等待处理的数据,也可以是待处理数据的内存地址。而操作码则描述将要对操作数进行何种处理。
需要强调的是,通常所说的64位指令,并不是指指令的全长或操作码的长度为64位,而是指操作数所能达到的最大位数为64位。通过下面的图示,我们可以很好地理解64位指令和64位处理器的本质。

64位指令工作原理示意图
由于操作数一般需要存放在通用寄存器中,因此64位处理器通用寄存器的尺寸也必须是64位。这样我们就很容易理解K8处理器里通用寄存器结构的上半部分(指RAX-RSP部分,下半部分我们后边再提)。如下图所示:

K8通用寄存器的扩展
从上面的图示可以看出,相对于传统的X86处理器而言,K8在进行64位扩展的时侯,把8个通用寄存器增加到了64位,同时增加了指令指针寄存器的位数为64位。
至于寻址方面,由于地址数据只不过是整数操作数中的一种,因此同样使用GPR。这样,64位处理器所能处理的地址数据长度自然就增加到了64位,从而大大增加了处理器的寻址空间。
当然,为了简化起见,以上我们所说的操作数,只不过是现代CPU所处理的操作数中的整数数据(地址数据)。它们由处理器中的ALU(算术逻辑单元)和AGU(地址生成单元)进行处理,一般使用通用寄存器(GPR)来保存。实际上,我们还需要处理通常保存在浮点寄存器、MMX以及XMM寄存器里的浮点以及其它多种数据。
不过,在我们进一步谈这些除了整数和地址数据外其它数据类型在64位处理器中的处理状况前,我们必须首先了解一些有关寄存器和数据类型的基本知识。
●寄存器和数据类型
我们知道:整数、地址、指令指针和浮点数据是按照数据形式来划分的,CPU所要处理的3种主要数据类型。此外我们还可以根据数据需要CPU进行处理的类型,来将它们分为标量数据和矢量数据两大类。
通常我们把需要CPU进行不同处理的单个数据称为标量数据(Scala Data)。标量数据既可以是整数数据,也可以是浮点数据。其中整数标量数据的存放区一般为通用寄存器(GPR),浮点标量数据的存放区一般为浮点寄存器(FPR)。
与标量数据相对的是矢量数据(Vector Data)。所谓矢量数据就是指一列需要由处理器作相同处理的数据集合。比如处理器在做MP3编码的过程中,需要对内存中的音频文件里的各字节数据作相同的MP3编码操作。那么通常使用MMX或SSE这类单指令多数据流(SIMD)指令,将数个字节打包为一组矢量数据,存放在MMX或SSE寄存器中,再送往相应的功能单元进行统一操作。
和标量数据一样,这些矢量数据既可以是整数数据,也可以是浮点数据。矢量数据以封包的形式批量存放在MMX(对于使用MMX、3DNow!进行操作的数据而言)和XMM(对于使用SSE、SSE2进行操作的数据而言)寄存器中。
通过下面的图,我们可以更好地了解标量数据和矢量数据的区别:
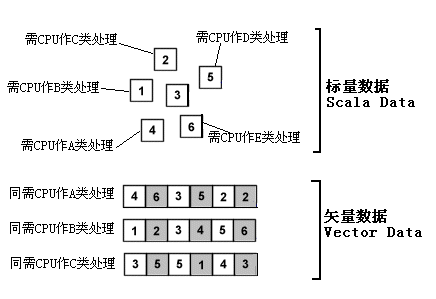
标量与矢量数据
我们整理了标量数据和矢量数据在X86-32位处理器以及AMD的X86-64处理器中所用寄存器的具体区别如下表:

实际上,MMX和XMM通过寄存器映射的方法,也可以参与标量浮点数据的存储。同时数据类型也远不止整数、浮点这两类基本数据类型,还包括有指令指针数据、BCD数据,位数据等。要把这些情况一一说清,显然不是一两篇文章能解决得了问题的。
幸好,这些省略的部分与我们的结论并没有影响,因此我们叙述时使用了简化的措施。需要更详细完整的资料,您可以参考Intel的IA32以及AMD的X86-64架构编程指导书。
从上表我们可以看见,K8的64位扩展部分似乎仅对于整数、地址数据有效。对浮点和向量数据则仍然保持原样。
经过上面的分析,我们似乎可以得出这样的结论,那就是:我们能从K8向64位的扩展所获得的好处,只不过是可以在同样一条指令中,处理更大数值的整数数值以及管理空间更大的内存区域而已。而在32位的情况下,由于通用寄存器只能容纳最大32位的数据,因此显然要花费更多条指令对尺寸超过32位的数据进行处理。
这种改进对服务器、科学计算这样的领域虽然具有一定的意义,但显然并不是普通家用环境急需的改进。试问在近期普通应用中,有多少情况下会用到超过232这样大的整数数值和超过4GB的内存空间呢?
然而,如果你因此低估了K8和X86-64指令集的实力,那就大错特错了。
X86-64分析(二):幸福在哪里,幸福在哪里
显然,K8体系不可能只是如我们上面所说的那样,仅仅简单地在64位环境下增加通用寄存器的宽度到64位。X86-64最吸引我们的部分应该在于对传统X86寄存器“体系”的变革上。
●寄存器体系的变革
我们都知道,X86指令集本身属于一种复杂指令集(CISC)。长期以来,使用X86指令集的处理器架构一直沿用寄存器结构。相比那些使用精简指令集(RISC)的处理器架构来说,由于程序可见的寄存器数量较少,因此造成传输延迟,性能以及流水线工作效率相对落后,从而给X86架构处理器的表现造成了影响。同时程序和编译器的优化难度也较大。
虽然近代的X86处理器中都增加了许多程序不可见的内部寄存器,并通过寄存器换名(Register Rename)技术变相地增大通用寄存器的数量,来弥补这一不足。然而这种措施由于只能通过处理器的硬件控制来实施,程序员无法根据需要来,灵活控制实际的寄存器使用状况,显然不如直接增加可见的通用寄存器来的有效。
而K8针对上述问题作出了改良。处理器在64位状态下工作时,增加了大量的程序员可见寄存器以供编程者使用,如下图:

可以说,这些额外增加的寄存器(我们姑且称之为“寄存器扩展“吧),才是真正能为桌面用户带来的好处之所在!
不过,尽管如此,我们也只能在K8的64位模式下,才能全部用到这些多出来的寄存器扩展资源(紫色部分的寄存器)。因为为了兼容以往的X86指令,K8所用的X86-64指令集将其所支持的指令分成了如下表所示的数个部分:
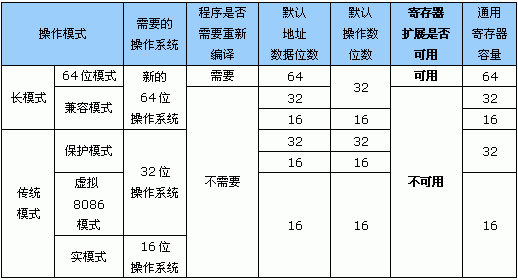
如上表所见,前面我们所说到的令人激动的寄存器扩展功能,并不是“即插即用“的。它需要我们将操作系统向64位转换,同时重新按64位的编程规范编译应用程序。在其它模式下,我们根本无法享受到这些好处。
尽管X86-64前途远大,不过古语云:天将降大任于斯人,必先……。以目前X86-64指令集64位扩展的各方面支持状况来说,情势不容乐观。
●操作系统的支持
从操作系统方面来看,目前除了部分版本的Linux率先支持X86-64位指令集64位扩展外,X86-64位指令集64位扩展真正走向主流所必不可缺的因素――Microsoft的视窗系列操作系统,相关的正式版却迟迟未能露面,仅在Athlon 64发布日匆匆推出了一款WinXP 64-bit beta版。
同时系统也仅配用了稍显老旧的Directx8.1,64位Directx9.0b则根本无法通过正常渠道获取。而通过上面摘自微软页面的说明,我们也可以看到WinXP 64-bit beta版的获取途径对于一款操作系统来说,也显得相当另类。这一切,多少令人感觉有点敷衍了事的意思。
●设备驱动的支持
从64位操作系统所必备的64位设备驱动程序来看,包括主板、显卡在内的许多重要设备的64位驱动程序也是犹抱琵琶半遮面,绝大多数设备厂商甚至在客服网页中也没有包含相关的下载文件,更不要提随盘附带64位驱动了。
在这方面,NVIDIA倒是率先提供了64bit版本的显示卡驱动程序,算是业内走在前列的厂商了。
●应用软件的支持
从64位最终的执行者――常用应用程序看,目前只有《UT2004》等极少数游戏宣称将推出64位版本的游戏。而更多的应用软件厂商则只是表示会支持,但多数都没有成品64位程序推出。
正是基于以上的原因,我们此次的评测,也没有添加64位的相关部分。
所有这一切,似乎映证着一句俗话:道路是曲折的,前途是光明的。
K8系统架构分析
尽管在X86-64的64位扩展上,AMD目前遇到了一些推广方面的阻力。然而作为世界上顶尖的处理器制造厂商之一,AMD仍然具备非凡的实力。他们的新王牌――K8显然在常规32位领域也作足了准备和Intel继续拼杀。这一部分目的的达成,在失去了指令集的优势后,就必须更多依赖整个系统的架构以及处理器的核心架构。在这个两方面,AMD也采取了许多措施,实现了K8的32位性能相对K7质的飞跃,从而完全具备了同Intel在32位领域一争高下的强大实力!
那么相比之下,K8在系统的架构这部分究竟有哪些主要的变动呢?下面我们就为大家做一些粗略的分析。
●旧有架构的缺陷
我们都知道:处理器主要同两类外部设备进行信息交换,其一是内存,其二是I/O设备(包括显卡、硬盘等等)。对于桌面系统而言,通常的做法是设置南北桥两个外置芯片,由外置的前端总线连接CPU和北桥,负责单个或多个CPU同内存和I/O设备的信息传输。
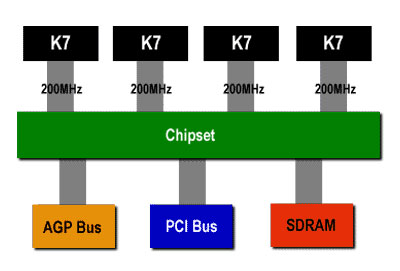
这方面的例子有AMD的上一代K7架构,如上图。它采用同为点对点传输的EV6前端总线技术,前端总线数据传输率数据传输率为总线运行频率的2倍,即200×2=400MHz。不过,虽然在处理器与北桥芯片之间使用点对点传输,然而多处理仍然必须共享集成在北桥里的内存控制器。
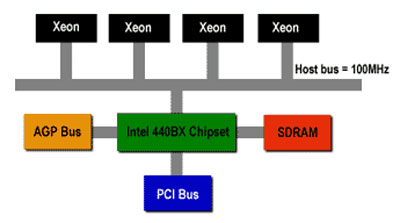
Intel P4 3.2GHz则仍使用沿袭自P6架构的多处理器共享式AGTL+前端总线技术,如上图。不过,Intel将前端总线数据传输率提升为总线运行频率的4倍,即200×4=800MHz。多处理器间不仅共享前端总线,同时还必须共享集成在北桥里的内存控制器。
这两种办法存在两个主要缺点,其一是由于前端总线和内存控制器外置,导致CPU同内存进行数据交换时的延迟较大;其二是由于AGP显卡等I/O设备和内存一起共享前端总线同单CPU或多CPU交流,特别是在多处理器的环境下,由于前端总线为多处理器共享,造成前端总线“交通拥挤“,效率不佳。
●全新架构的改良
因此,新的K8核心处理器使用了全新的北桥架构,把旧有北桥一分为二,将传统北桥的内存控制器和北桥总线接口内置到CPU核心中,而传统北桥中的AGP控制器以及同南桥进行数据交换的接口界面则仍然外置。新的北桥架构通过外置Hypertransport总线将北桥的内置部分同外置部分的AGP控制器等连接在一起。下面,我们给出传统系统结构与K8结构的区别图如下:

传统系统结构与K8结构的区别图
对于Athlon64、Athlon64 FX51以及Opteron14系列处理器来说,内置北桥具备一条最大位宽16bit,最大运行频率800MHz的双向传输Hypertransport总线。它同外置的北桥其余部分进行连接,峰值带宽达到了6.4GB/s,超过了以前K7系统的3.2GB/s,与Intel P4的6.4GB/s持平。
虽然数值上与Intel P4的6.4GB/s持平,但是不要忘记,Hypertransport支持双向点对点传输,况且从原来的外置北桥中移走了内存部分。而对于Opteron的其它系列处理器来说,这个连接数目则增加到3条,使Opteron具备连接多处理器的能力。
通过使用新的北桥架构和新的总线,改正了旧北桥结构的两个主要缺点,使处理器同内存、外设接口的性能获得了较大的提升。
说到HyperTransport总线,就必须提一提它的灵活多变特性。
与我们熟悉的传统前端总线可调总线运行频率,位宽固定为64bit所不同的是,HyperTransport总线具备传输位宽、传输频率可调的特征。
虽然Athlon64 FX所具备的HyperTransport总线接口,最大运行频率和上下行总线位宽分别为800MHz――由于HyperTransport总线采用类似DDR内存的双倍数据传输率的技术,因此其数据传输率还应×2,即为800×2=1600MT/s――和16bit。
然而实际应用中总线的运行频率和总线位宽都可以作出灵活的变动。频率方面有200/400/600/800MHz等多种选择。上下行位宽方面也有2/4/8/16bit等多种选择,同时上行位宽与下行位宽之间也不必保持一致。具体如下表:

Hypertransport总线多变的参数
这就出现众多支持K8处理器的外置北桥,各自采用不同的HyperTransport总线运行频率以及不同上下行位宽的混乱局面。这一点,请大家在接触K8平台时要特别注意。在我们的《新多元方程:nForce3 Pro 150技术解析》一文中,也因此作出了一些错误的判断。
当时我们将NVIDIA公司的K8平台芯片组――nForce3 Pro 150的最高运行频率误判为450MHz,上下行位宽误判为16/16bit,事实证明这个结论是错误的。
为此,我们列出根据官方声明更正后的各大厂家生产的K8平台北桥芯片组的HyperTransport接口特性,如下表:
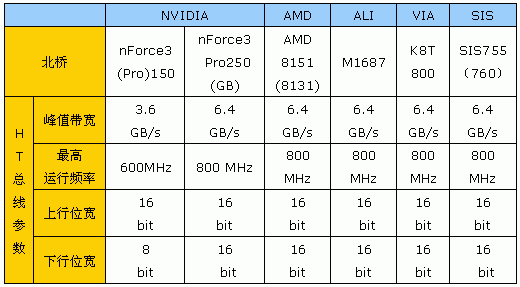
至于最近大家争论不休的nForce3(Pro)150数值上显得较低的3.6GB/s总线峰值带宽,会不会给系统性能造成影响,我们留待后面的评测部分为大家揭开谜底。
除此之外,HyperTransport总线还具备双向差分传输等与传统总线所不同的特殊结构特性。关于这些特性,在各种媒体中均已经有了较为详尽的阐述,我们在此就不再多言了。
处理器核心分析
外围系统架构的变革,归根到底还是为处理器内核服务。如果这一部分不作出改进,性能上的提升,也只能是一纸空文。
首先,我们来看两张K8核心的Athlon64(FX)与K7核心处理器的内部架构对比图:
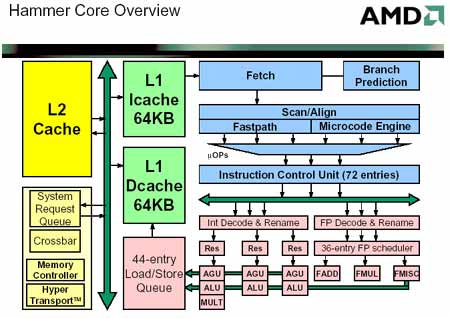

Athlon64(FX)与K7内部架构对比
图中可见,表面上看新的核心和K7相比总体上变化并不大,同样的3个负责整数运算的ALU、AGU单元,同样的3个负责浮点、3DNow!等多媒体指令运算的浮点单元。如果不考虑新的64位指令执行状况,基本上两者处理数据的流程将非常相似。
但是较为仔细地了解了新核心的内部结构后,你会发现即使对于32位指令的执行来说,虽然他和K7相比外貌相似,实际上还是存在几处较为明显的区别的。
我们首先从前端的缓存部分入手吧:
●缓存部分的改进
一级缓存、二级缓存部分,Athlon64(FX)同K7核心相比,除了将二级缓存容量统一提升到1MB,二级缓存位宽相比K7核心的64bit倍增为128+12bit之外,并没有在结构上作出太大的变动。
然而,CPU中另一类重要缓存---主管内存地址翻译的TLB的相关参数,却在Athlon64(FX)中相对K7处理器做出了较大的变动。
为了使大家更透彻地理解TLB的参数变化对CPU性能的影响,关于TLB的原理,我们作出如下的简要介绍:
TLB的英文全名为:Translation Lookaside Buffer,我们可以翻译为旁路转换缓冲,也可以把它理解成页表缓冲,因为它里面其实存放的是一些页表文件(虚拟地址到物理地址的转换表)。
首先我们需要知道的是:TLB和我们熟悉的一级、二级缓存并没有本质的区别,二者都属于缓存一类,他们的区别在于所缓存的内容不同。我们知道,同CPU在内存中存取数据时先查找一级、二级缓存中是否存在所需的数据相同;当处理器要在内存中寻址数据时,它也不是直接到内存的物理地址里查找的,而是通过一组虚拟地址转换到主内存的物理地址。
这样,就需要有一组将虚拟地址和物理地址对应起来的地址对应表格。通常,这个表格存放在内存中,TLB则负责缓存这个表格中的数据。而CPU需要寻址数据时,同样会优先在TLB中查找是否有需要的表格数据。这样,同一级、二级缓存尺寸和联合路数对处理器性能的影响相同,处理器的性能和寻址的命中率,进而同TLB的尺寸、联合路数有很大的关系了。
对于寻址空间更大的K8,增加TLB条目数,改变TLB联合方式显然具有更重要的意义。
回到正题,我们整理了AthlonXP与Athlon64(FX)相关的TLB参数的不同之处,列出以下的表格,供大家参考:

以下则是我们使用Wcpuid3.1a所测出的Athlon 64 FX51以及Athlon 64 3200+的缓存相关信息(两者信息相同,不重复贴出):

Athlon64 FX51缓存相关信息
同时,在TLB控制机构方面,为了提高在程序间切换时的处理器性能,Athlon64(FX)也相应K7核心作出了一些变化。具体变化大家可以参考如下的Athlon64(FX)TLB机构图:

新的TLB控制机构
●流水线级数增加
总体上看,整数流水线部分,Athlon64(FX)具备12级流水线,相比K7的10级流水线增加了2级;浮点流水线部分,流水线深度则增加到17级,相比K7核心的15级增加了2级。


K8和K7的流水线
增加的流水线级数,显然有利于提升处理器的频率。然而相对P4的超长20级管线对提升处理器频率的贡献来说,Athlon64(FX)仍然较小,这也暗示了Athlon64(FX)处理器频率仍然将落下风的结局。不过幸好大家都已经清楚对于不同的处理器架构来说,处理器运行频率与实际性能之间并不存在简单的正比关系。
另外,还有一点要提的是:从许多资料上,大家可能会看到诸如K8流水线深度增加到32级之类的说法,这是由于加入了内部整合的内存控制器执行阶段。至于传统意义上的核心部分,流水线深度则应为12级和17级。
以下,我们顺着流水线的走向,来看看K8的核心部分与K7的异同之处。
●指令取和分支预测部分
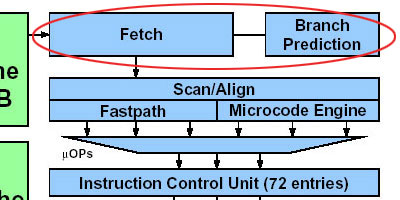
这部分的变化,主要在于分支预测单元部分所作出的改变。此部分许多媒体已经作了介绍,因此我们不再重复,只作简要说明。
由于流水线长度的增加,为了减小分支预测失败给处理器性能造成危害的可能性,K8相对于K7在其分支预测部分作出了一些改进,其中包括使用新的分支预测算法,将Global History Counter的条数增加到16K,为原来K7的4倍之多,加入可快速、准确地计算出下一条分支指令地址的Branch target address calculator等。通过这种改进,AMD宣称其分支预测精准度将比K7提高18%。
●解码部分

接下来,进入到解码部分。
解码部分的出口保持与K7一致,仍然为3个。不过,在K8的解码部分中,更多的指令将籍由硬件解码器(AMD称之为Fastpath或Directpath)而不是送往速度相对较慢的Mircocode单元中执行解码,比如原来需要借助Mircocode单元解码的SSE矢量数据处理指令,现在则完全由Fastpath单元担任解码工作,加强了执行SSE指令的处理效率。此外,由于K8处理器加入了对SSE2指令集的支持,很显然K8解码部分也因此相应作出了一些变化。
考虑到读者可能对Fastpath和Mircocode的概念比较陌生,这里我们对此进行一些解说:
我们都知道,要对一条X86指令进行解码,必须使用一些翻译机构。目前来看,使用的翻译机构不外乎两种:
一种是纯硬件的处理单元直接翻译,K8中的Fastpath指的就是这类单元;
另一种则是使用微编程(Microprogaming)的办法,将μOp(微指令)预先存储在MicroROM(MROM)内部,然后根据外部输入的指令来判定需要到MROM中选取那些μOp输出,K8中的Mircocode指的就是这类单元。
下面的图能帮助大家更好地理解这两种解码方式:
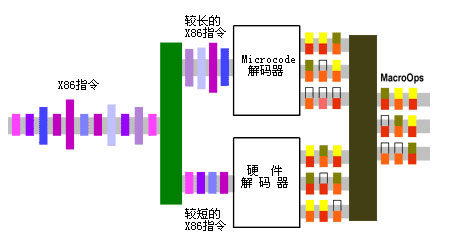
Fastpath和Mircocode解码原理图
两种办法互有优劣,纯硬件的解码器由于没有MROM的延迟问题,因此执行速度快,Fastpath也是因此而得名;但是,这需要相对复杂的硬件机构实现。特别对于X86这种复杂指令集而言,如果全部使用硬件处理单元直接翻译,势必导致解码处理单元数量的剧增;而Mircocode单元虽然从硬件上实施起来相对简单,同时很适合复杂指令集的口味,但是相对纯硬件的解码单元,存在延迟较大的缺点。
由于两者互有优劣,因此目前执行X86指令集的处理器解码单元中,通常都设置了这两种结构同时进行指令的解码翻译工作,通常由硬件解码器(Fastpath)负责包含μOp数目较少的短指令的解码,而由Microcode解码器负责包含μOp数目较多的长指令的解码。
●执行部分
接下来,经过解码的μOp,通过解码单元的3个出口顺着指令路径进入到处理器的发动机――执行部分。

首先进入执行部分的ICU(指令控制单元),Intel又称ROB(微指令池)部分。此部分的任务是负责缓存由解码单元而来的μOp,协调它们输出到具体执行单元的顺序,负责处理执行过程中出现的异常情况等。在执行单元中担任十分重要的角色。不过,在K8中此部分参数基本没有变化,其所能容纳的μOp数目仍然保持为原来K7的72条。出口方面,显然也还是相同的3条出口。
由ICU出口处送出(Dispatch)的μOp(微操作),将视其类型分别送往浮点/多媒体指令执行部分或是整数/地址指令处理部分。
●指令调度部分
在执行部分中,MacroOp从ICU送出后,还要先送往浮点/多媒体指令执行单元或是整数/地址指令处理单元各自的指令调度器(Integer/FPU Scheduler)中进行进一步处理。
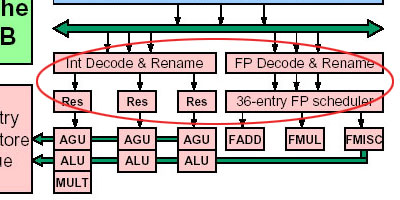
指令调度器对超标量处理器的执行效率意义重大,我们以整数/地址指令调度器(Integer Scheduler)―又称Reservation station(Res)为例,介绍指令调度器。它的工作大致可分以下三部分:
其一是负责在指令执行相对较慢的整数单元和指令送出(Dispatch)速度相对较快的ICU单元之间负责缓冲作用。其缓冲能力与指令调度器内部所能存放的μOp条目数(entries)成正比――单从这一点上看,与一、二级缓存的容量和其在处理器与内存之间所能起的缓冲作用的关系十分类似;
其二是负责将ICU送来的μOp,根据μOp的类型,将其分别送往(issue)AGU或ALU;
其三是根据存放操作数的寄存器以及AGU/ALU的空闲状况,负责安排好μOp送往AGU/ALU单元的次序。对于超标量处理器而言,指令的正确调度,对于避免出现流水线危机(Pipeline Hazard)的作用十分重大。
在K8中,为了加强整数部分的性能,该部分所用的指令调度器所能缓冲的μOp条目数由原来的18条增加到了24条。增加整数指令调度器的μOp条目数,显然是当心较慢的整数执行单元或是频繁使用的寄存器会使前面发布μOp的ICU陷入等待状态。
●整数执行单元和浮点/多媒体指令执行单元
接下来,指令进入整数执行单元或浮点/多媒体指令执行单元。
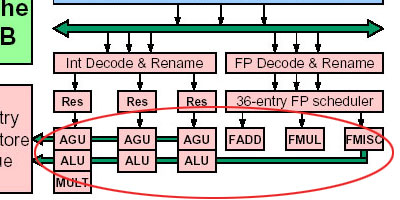
整数处理单元仍然由3个AGU、3个ALU组成。不过,在执行整数乘法时,K8核心的整数乘法单元(MULT)在处理32位整数数据乘法操作时,延迟由K7的4个周期减小为3个周期,具体如下表:

改进的整数乘法执行效率
浮点/多媒体指令执行单元部分则基本没有变化,仍然是原来的FADD、FMUL以及FMISC三个部分。强大的浮点单元应该令AMD感到十分放心。
不过对于多媒体指令特别是新增的SSE2指令处理方面,在执行阶段,可以说基本同K7不会有什么太大的区别,这方面唯一的改进,应该在我们刚才提及的解码部分,加快了这类指令的解码速度。
以上我们粗略为大家介绍了K8处理器核心部分的改进。希望对大家理解新的K8核心能起到一定的参考作用。
●参数的白璧微瑕:nForce3系列芯片组
尽管K8系列处理器已经在处理器内集成了北桥的一部分,但仍不能缺少外置芯片组的支持。这方面目前为止主要有5家厂商为AMD K8处理器生产其配套芯片组,他们已经推出的产品分别有:NVIDIA的nForce3系列芯片组、VIA的K8T800系列芯片组、AMD的8000系列芯片组、ALI的M1687+M1563芯片组、SiS的SiS760+SiS964、SiS755+SiS964。如此多厂商加入K8平台的角逐,形成了K8平台上除处理器外的另一个战场。
我们还是来逐个看看各大芯片组厂商推出的K8芯片组具体情况吧。
●参数的白璧微瑕:nForce3系列芯片组
NVIDIA在nForce2系列主板上取得的不俗成绩,已经得到大家的认可。随着K8的推出,与AMD关系紧密的NVIDIA当然也不会错过这个大好机会。
根据我们目前的信息,他们将推出nForce3(Pro)系列共计6款芯片组,其中已经正式推出的就有5款。NVIDIA以实际行动给予AMD K8莫大的支持。
除了我们为大家介绍过的服务器/工作站平台用nForce3 Pro 150(Crush K8)、nForce3 Pro 250(Crush K8S)以及目前为止仍未见踪影的Crush K8G以外,在最近一段时间内NVIDIA又进一步完善了其产品线。
◎新面孔一:nForce3 150
为了对应桌面型Athlon64 FX,NVIDIA新推出了nForce3 150芯片组。此款芯片组与先前的nForce3 Pro 150规格相差不大,唯一的区别在于前者支持的CPU为754接口的Athlon 64,而后者则支持940接口的Athlon 64 FX以及Opteron。
◎新面孔二:nForce3 Pro 250Gb
此外,NVIDIA还进一步完善服务器/工作站的芯片组阵营,添加了内部整合千兆网卡的nForce3 Pro 250Gb,同样,他与nForce3 Pro250除了内部整合千兆网卡,也没有太大的区别。
◎新面孔之三:nForce3 Go150
至于nForce3 Go 150则为150的移动版本,支持PowerNow!技术。因此我们认为:相比其他芯片组厂商而言,nForce3系列芯片组的看点在于:
-整合南北桥设计,相对其它厂商而言较低的桥间传输延迟;
-颇具争议性的北桥-CPU带宽问题;
-齐全的K8芯片组阵营;
-谜一般的Crush K8G。
我们还制作了如下的NVIDIA最新nForce3桌面系列芯片组特性对比,以供大家参考:
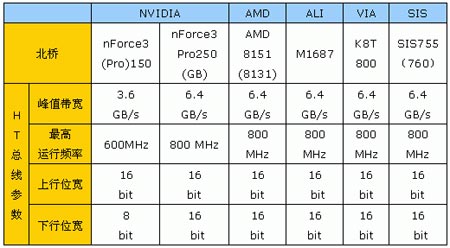
这里需要提醒大家注意的是,在nForce3 Pro250Gb上,HyperTransport总线带宽的参数已经提升到了6.4GB/s。
五十步笑百步:VIA K8T800芯片组
作为AMD的另一个重要合作伙伴,VIA也推出了自己的K8T800系列芯片组以支持K8处理器。K8T800芯片组由北桥VT8385+南桥VT8237构成,以下是使用VT8385+VT8237的K8T800芯片组系统组成结构图:
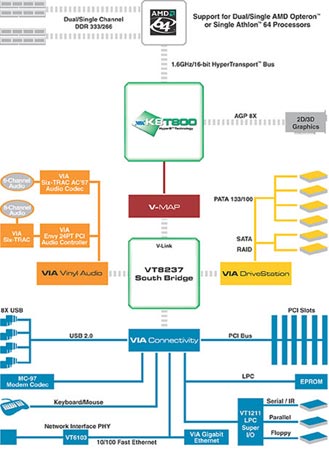
K8T800芯片组系统组成结构图
VIA给用在它们主板上的HyperTransport总线技术起了一个很好听的名字,叫做Hyper8。从这张图里我们可以直接看到VT8385与CPU间HT传输总线的数据传输率为800MHz×2=1600MHz,同时上下行皆最大支持16bit的位宽。这样如我们前面为大家介绍的那样,其峰值带宽就为6.4GB/s。
有此资本在手,VIA显然不会忘记在其官方网页上标榜一番,同时不忘抓紧时机“郁闷”一下对手NVIDIA。上图就是截自VIA官方网站的原文页面,从划红底线的部分我们不难看出这句话的攻击矛头直指NVIDIA。
现阶段K8芯片组中只有NVIDIA的nForce3 Pro 150符合这段话的描述。不过这里的3.2GB/s似乎应该改正为3.6GB/s为宜。看来,在火药味十足的K8芯片组市场,VIA是铆足了劲要和NVIDIA大干一场了。不过,VIA K8T800也并非无懈可击,他们的问题在于其VT8237南桥与VT8385北桥间的连接带宽。
在K8T800上,VIA继续使用其连接南北桥的V-Link总线技术,该总线主要指标如下:
◎总线位宽为16bit;
◎总线工作频率为66MHz,并使用类似AGP8×的8×数据传输率技术,这样其数据传输率就应为66 MHz×8=533MT/s。
值得一提的是,当连接在V-Link总线一头的VT8385北桥工作在这个最高数据传输率时,却只能以半双工的模式进行南北桥的数据传输,这样其南北桥数据传输峰值带宽便为:
533 MT/s×(16/2)/8=533MB/s
而相比之下,连在V-Link总线另一头的VT8237本身则完全可以支持533MT/s时的全双工工作模式。只不过受到VT8385北桥上述特性所限,因此导致K8T800芯片组南北桥数据传输峰值带宽仅为533MB/s。这也使K8T800成为所有目前为止发布的芯片组中,南北桥数据传输峰值带宽最低的一款芯片组。
在产品分类方面,VIA则将K8T800按照面向的应用范围不同而分成了两种,一种面向服务器和工作站,另一种则面向现在的桌面PC。这两者的不同主要在于,一个支持Opteron,而另一个是支持Athlon 64。面向服务器和工作站的版本还可以支持PCI-X标准。由于内存控制器已经内置到了CPU当中,所以这一项和主板本身的设计关系不大。
而关于这款芯片组的南桥方面则采用的是内置功能较多的VT8237,它们所支持的功能包括内建的VIA Viny Audio 5.1环绕声卡,2×ATA133+2×SATA硬盘接口,以及SATA接口的RAID功能,10/100M内建网卡等。此外,通过VIA VPX2 I/O扩展桥还可以支持服务器/工作站平台上常见的PCI-X设备。
综上所述,我们认为VIA K8T800芯片组的看点在于以下3处:
- Hyper8所带来的参数优势,可能为VIA带来的切实性能领先;
- K8T800芯片组较低的南北桥数据传输带宽,可能会对系统整体表现造成影响;
-丰富的南桥内置功能。
不声不响发大财:AMD 8000系列芯片组
AMD自己的芯片组配合自己的CPU,可谓是门当户对了。目前AMD的K8平台相关芯片组产品主要是AMD8000系列芯片组。该系列芯片组由充当北桥的AMD8151或AMD8131以及充当南桥的AMD8111组成,如下图:

AMD8000系列芯片组结构图
从上图可以看出AMD-8131由两大功能模块(HT Tunnel+ PCI-X Bridge)组成,HT Tunnel这个通道内分有两个接口端,SideA通过HT总线连接到K8 CPU,SideB则通过HT总线连接到后端的8111南桥。
●AMD8131
这里需要注意的是,虽然AMD8131两端都采用了HyperTransport总线连接,但是A和B两端的HT传输总线的位宽是不同的,A端为双向16位,B端则为双向8位。同时AMD8131还拥有两个PCI-X Bridge(BridgeA+BridgeB),独具PCI-X支持;
此外AMD8131两端HyperTransport总线的最高运行频率也不相同,在A端是800MHz×2=1.6GHz,这样它和CPU间的最大数据传输带宽就是6.4GB/s;而在B端则最高频率仅为400 MHz×2=800MHz。
●AMD8151
而AMD-8151的架构和AMD-8131类似,也是分成A和B两个HT传输端口,A和B端的对应HT传输总线位宽同样为双向16位和双向8位;并且两端传输总线的时钟频率也不相同。
●AMD8111
AMD-8111则相当于传统的南桥芯片,上面的结构图中我们可以看到它和AMD-8131/8151进行通讯的部分采用的是8位上行和8位下行的双向HT总线,同时最高具备200MHz×2=400MT/s的数据传输率,这样它和AMD-8131/8151进行通讯的最大带宽就是400MT/s×(8+8)÷8=800MB/s。
此外,AMD8111在硬盘接口方面提供两个可支持ATA133的EIDE接口,网络设备方面则内部仅集成10/100M网卡功能。
不过,不知出于什么原因,在使用其它厂家芯片组的主板纷纷推出的同时,市场上却鲜见使用AMD芯片组的主板。这不能不说是个遗憾。
我们绝不盲从:ALi M1687+M1563芯片组
如此多的厂家都提供了自己的K8平台解决方案,ALI公司当然也不甘落后,他们也推出了M1687+M1563的K8平台。以下为M1687+M1563的系统构架图:
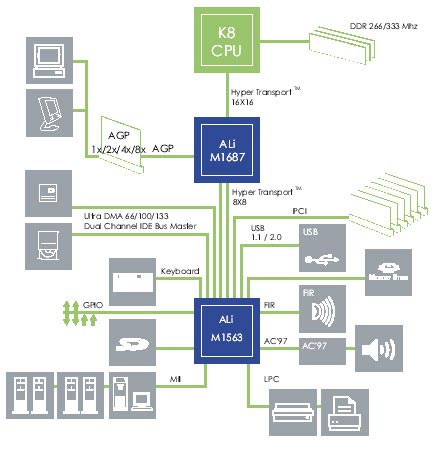
M1687+M1563的系统构架图
有趣的是虽然ALI为这套芯片组的北桥取名为M1687,但是我们在实测中却发现实际上这块芯片其实就是AMD的8151芯片组!ALI官方则宣称M1687是其与AMD合作研发的产品。
既然如此,考虑到我们上面已经介绍了AMD8151的相关参数。因此举一反三,我们很自然地就可以想到其南北桥芯片组也是采用HyperTransport技术进行连接。
不过值得注意的是,尽管北桥使用AMD8151,但是与AMD8111只能支持200MHz的总线频率不同,ALi的ALi1563将所支持的HyperTransport总线最高频率提高到了400MHz,同时保持最大上下行位宽仍为8bit。这方面ALi没有盲从AMD8111的参数设计。因此相比AMD8151+AMD8111的组合实现了南北桥数据传输最大峰值带宽的倍增!这样我们将800MB/s×2,就得到其相应的最大带宽为1.6GB/s。
至于北桥和CPU之间,由于采用的同为AMD8151,自然是同样的最大6.4GB/s的传输位宽了。除此以外,南桥方面则没有太多的亮点,平庸的2×ATA133硬盘接口和内建10/100M网卡功能。
因此,对于ALI的M1687+M1563芯片组而言,其看点:
-高达1.6GB/s的南北桥数据传输最大峰值带宽。
坚决让963L下课:SiS755和SiS760
台湾的另一家芯片组大厂SiS则推出了SiS755和SIS760领衔的两款芯片组为K8助阵。以下是这两套组合的系统结构图:
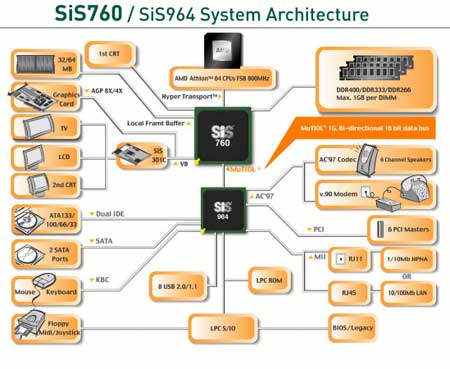

SiS755和SIS760系统结构图
与早先公布的芯片组组合所不同的是,在最近SIS的官方网站上放出的数据表明:SIS终于下决心弃用了老旧的SiS963L南桥。SiS755改用北桥SiS755+新南桥SiS964的组合。北桥与CPU间的数据传输最大峰值带宽同大多数芯片组一样是6.4GB/s,南北桥之间则使用数据传输峰值带宽为1.06GB/s的妙渠(MultiI/O)技术进行连接。
而SiS960其余参数不变,同时在北桥内部整合其Ultra256显卡(仅支持DirectX 8.1),同样配用较新的SiS964南桥。尽管内置显卡的实际性能我们尚不得而知,不过SiS毕竟是首家敢于在成品K8系列芯片组中集成显卡的厂商,这样的勇气值得称赞。
新南桥SiS964相比老旧的963L加入了许多新的集成功能,增加了2×SATA通道,同时还提供了RAID功能的支持。为SiS的K8平台增添了几分靓丽的色彩。
因此,对于SIS的760/755芯片组而言,我们认为其看点在于:
-新加入的SIS964南桥丰富的新增内置功能;
- SIS760内部整合Ultra256显卡的实际性能表现如何。
全面回头大总结:K8芯片组特性展

从上面的芯片组介绍,大家可以体会到如此多支持K8的芯片组厂商都纷纷推出了自己的K8平台芯片组,真可谓是乱花渐欲迷人眼。为此我们特别整理了如下的表格,以供大家参考对比。考虑到我们在上面已经贴出了nForce3芯片组的较全面表格,因此在上面的表格中我们只选取主流桌面市场上大家比较感兴趣的nForce3 Pro 150来做对比。
PCPOP-电脑时尚 文/小胖胖
相关视频















相关阅读 Windows错误代码大全 Windows错误代码查询激活windows有什么用Mac QQ和Windows QQ聊天记录怎么合并 Mac QQ和Windows QQ聊天记录Windows 10自动更新怎么关闭 如何关闭Windows 10自动更新windows 10 rs4快速预览版17017下载错误问题Win10秋季创意者更新16291更新了什么 win10 16291更新内容windows10秋季创意者更新时间 windows10秋季创意者更新内容kb3150513补丁更新了什么 Windows 10补丁kb3150513是什么
- 文章评论
-
热门文章
 机甲mesuit好用吗 机甲
机甲mesuit好用吗 机甲 优酷路由宝怎么样 优酷
优酷路由宝怎么样 优酷 小米移动电源怎么样?
小米移动电源怎么样? 百度影棒怎么样?百度影
百度影棒怎么样?百度影
最新文章
 酷睿 i7-12700F处理器
酷睿 i7-12700F处理器 锐龙r5 3600和i5 1040
锐龙r5 3600和i5 1040
amd 5700显卡和2060对比 amd 5700xt和2070哪1660和1060哪个好 1660和1060性能差别对比黑加手环和小米手环3nfc哪个好 黑加手环和小apple pencil2代怎么样 apple pencil2代区别
人气排行 sata2和sata3接口区别评测小米AI音箱和小爱音箱mini版有什么区别 小爱挖矿用什么显卡比较好 2017挖矿显卡排名1660和1060哪个好 1660和1060性能差别对比a8和a9架构cpu的差别百度影棒怎么样?百度影棒一手评测赛钛客mmo7鼠标使用评测AMD Ryzen 7 1700x/1800x用什么主板?AMD R
查看所有0条评论>>